Hierarchical clustering of networks
Hierarchical clustering is one method for finding community structures in a network. The technique arranges the network into a hierarchy of groups according to a specified weight function. The data can then be represented in a tree structure known as a dendrogram. Hierarchical clustering can either be agglomerative or divisive depending on whether one proceeds through the algorithm by adding links to or removing links from the network, respectively. One divisive technique is the Girvan–Newman algorithm.
Contents |
Algorithm
In the hierarchical clustering algorithm, a weight 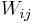 is first assigned to each pair of vertices
is first assigned to each pair of vertices 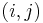 in the network. The weight, which can vary depending on implementation (see section below), is intended to indicate how closely related the vertices are. Then, starting with all the nodes in the network disconnected, begin pairing nodes in order of decreasing weight between the pairs (in the divisive case, start from the original network and remove links in order of decreasing weight). As links are added, connected subsets begin to form. These represent the network's community structures.
in the network. The weight, which can vary depending on implementation (see section below), is intended to indicate how closely related the vertices are. Then, starting with all the nodes in the network disconnected, begin pairing nodes in order of decreasing weight between the pairs (in the divisive case, start from the original network and remove links in order of decreasing weight). As links are added, connected subsets begin to form. These represent the network's community structures.
The components at each iterative step are always a subset of other structures. Hence, the subsets can be represented using a tree diagram, or dendrogram. Horizontal slices of the tree at a given level indicate the communities that exist above and below a value of the weight.
Weights
There are many possible weights for use in hierarchical clustering algorithms. The specific weight used is dictated by the data as well as considerations for computational speed. Additionally, the communities found in the network are highly dependent on the choice of weighting function. Hence, when compared to real-world data with a known community structure, the various weighting techniques have been met with varying degrees of success.
Two weights that have been used previously with varying success are the number of node-independent paths between each pair of vertices and the total number of paths between vertices weighted by the length of the path. One disadvantage of these weights, however, is that both weighting schemes tend to separate single peripheral vertices from their rightful communities because of the small number of paths going to these vertices. For this reason, their use in hierarchical clustering techniques is far from optimal.[1]
Edge betweenness centrality has been used successfully as a weight in the Girvan–Newman algorithm.[1] This technique is similar to a divisive hierarchical clustering algorithm, except the weights are recalculated with each step.
The change in modularity of the network with the addition of a node has also been used successfully as a weight.[2] This method provides a computationally less-costly alternative to the Girvan-Newman algorithm while yielding similar results.
See also
References
- ^ a b M. Girvan and M. E. J. Newman. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 99, 7821–7826 (2002).
- ^ M. E. J. Newman. Fast algorithm for detecting community structure in networks. Phys. Rev. E 69, 066133 (2004).